Rester connecté
Veuillez vous inscrire à la newsletter Maxxton et rester connecté avec les dernières nouvelles et idées clés.
Votre base de données regorge de données clients prêtes à être exploitées. Si la mise en place de campagnes ou l’élaboration de rapports stratégiques vous passionne, voici un élément clé à prendre en compte : le risque de données corrompues ou dupliquées. Imaginez les défis posés par la présence de multiples enregistrements d’une même personne dans votre base de données. Trier et éliminer ces doublons représente une tâche considérable et sujette à erreurs. Cependant, le Machine Learning offre une solution.

Au fur et à mesure que les entreprises accumulent des données de différentes sources et canaux, le risque de rencontrer des enregistrements dupliqués augmente significativement. Ces doublons peuvent résulter de fautes de frappe, de variations dans la saisie des données, de la fusion de bases de données, ou même de changements dans les informations client au fil du temps. Non résolus, les enregistrements clients dupliqués peuvent compromettre les relations avec les clients, conduire à des opportunités manquées et ultimement affecter les résultats financiers.
La mise en œuvre de la déduplication client par Machine Learning offre de multiples avantages :
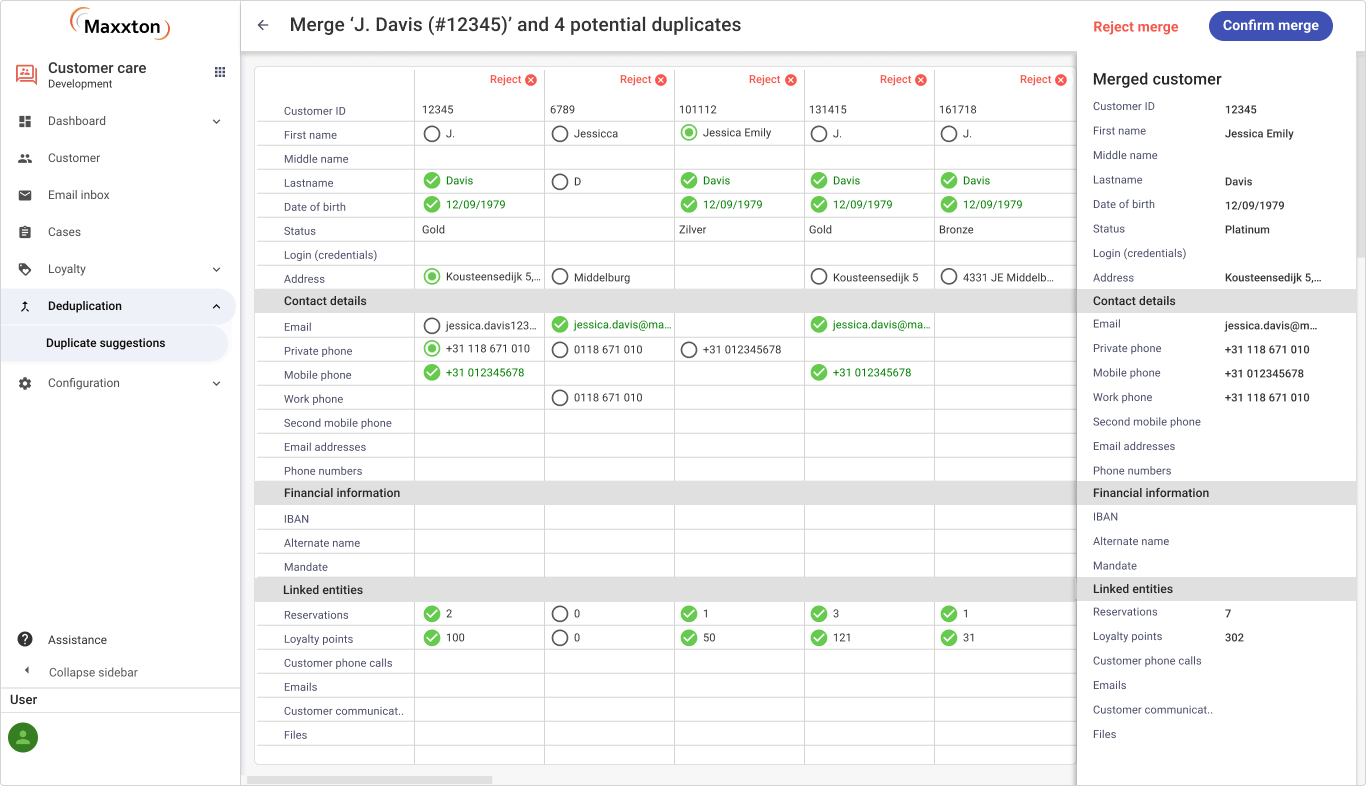
Notre nouvelle fonctionnalité logicielle tire parti de l’IA et de la science des données pour identifier et résoudre efficacement les problèmes de doublons dans le module Service Client de Maxxton. En analysant les modèles complexes de vos données, notre système distingue intelligemment les identités réelles des clients des similitudes fortuites. Ce processus, qui se déroule en sept étapes clés, assure une gestion optimale de vos données.
1. Prétraitement des données
L’étape initiale consiste à prétraiter les données brutes des clients afin d’éliminer les incohérences, de normaliser les formats et d’améliorer la qualité des données. Il s’agit par exemple de convertir le texte en majuscules, d’appliquer un modèle cohérent pour les numéros de téléphone et de supprimer les caractères spéciaux tels que les trémas ou les signes diacritiques. Ce processus est essentiel car il jette les bases d’une déduplication précise.
2. Extraction des caractéristiques
Des caractéristiques clés sont extraites des enregistrements des clients, telles que les noms, les adresses, les numéros de téléphone et les adresses électroniques. Ces caractéristiques servent de base à l’évaluation de la similarité des clients.
3. Calcul de la similarité
Des algorithmes d’apprentissage automatique sont utilisés pour calculer la similarité entre les paires d’enregistrements de clients. Le système examine une multitude de facteurs et attribue un poids plus important aux caractéristiques qui sont des identifiants plus fiables.
4. Personnalisation des règles
Pour une meilleure personnalisation, le système utilise des règles qui peuvent être ajustées pour chaque client afin de spécifier des conditions telles que l’exigence d’une correspondance dans les adresses électroniques ou d’un certain pourcentage de correspondance pour les noms de famille (par exemple, 90 %). Cela permet de s’adapter aux exigences spécifiques de l’entreprise. Nous reconnaissons que des fautes de frappe peuvent se produire dans les réservations téléphoniques ou en front office, y compris des variantes telles que Lynn, Linn et Lin. En outre, il peut y avoir des caractères spéciaux propres à un pays, par exemple Kreidestrasse – Kreidestr. – Kreidestraẞe. Notre système calcule si ces cas représentent des fautes de frappe ou s’ils indiquent réellement un nom ou une rue différents.
5. Détermination du seuil
Les scores de similarité calculés sont ensuite comparés à un seuil prédéfini. Les enregistrements qui dépassent ce seuil sont signalés comme des doublons potentiels.
6. Examen et confirmation manuels
Bien que le système réduise considérablement les faux positifs, les enregistrements marqués ne sont pas automatiquement fusionnés. Ils sont présentés aux utilisateurs pour examen. Cela permet de s’assurer qu’aucune donnée client authentique n’est modifiée par inadvertance.
7. Apprentissage continu
Le système propose des suggestions sur la fusion des données et les utilisateurs donnent leur avis en apportant des modifications ou en maintenant le statu quo. Ce retour d’information contribue à améliorer les recommandations du système. Le modèle d’apprentissage automatique apprend en permanence et affine ses algorithmes, améliorant progressivement la précision au fil du temps.
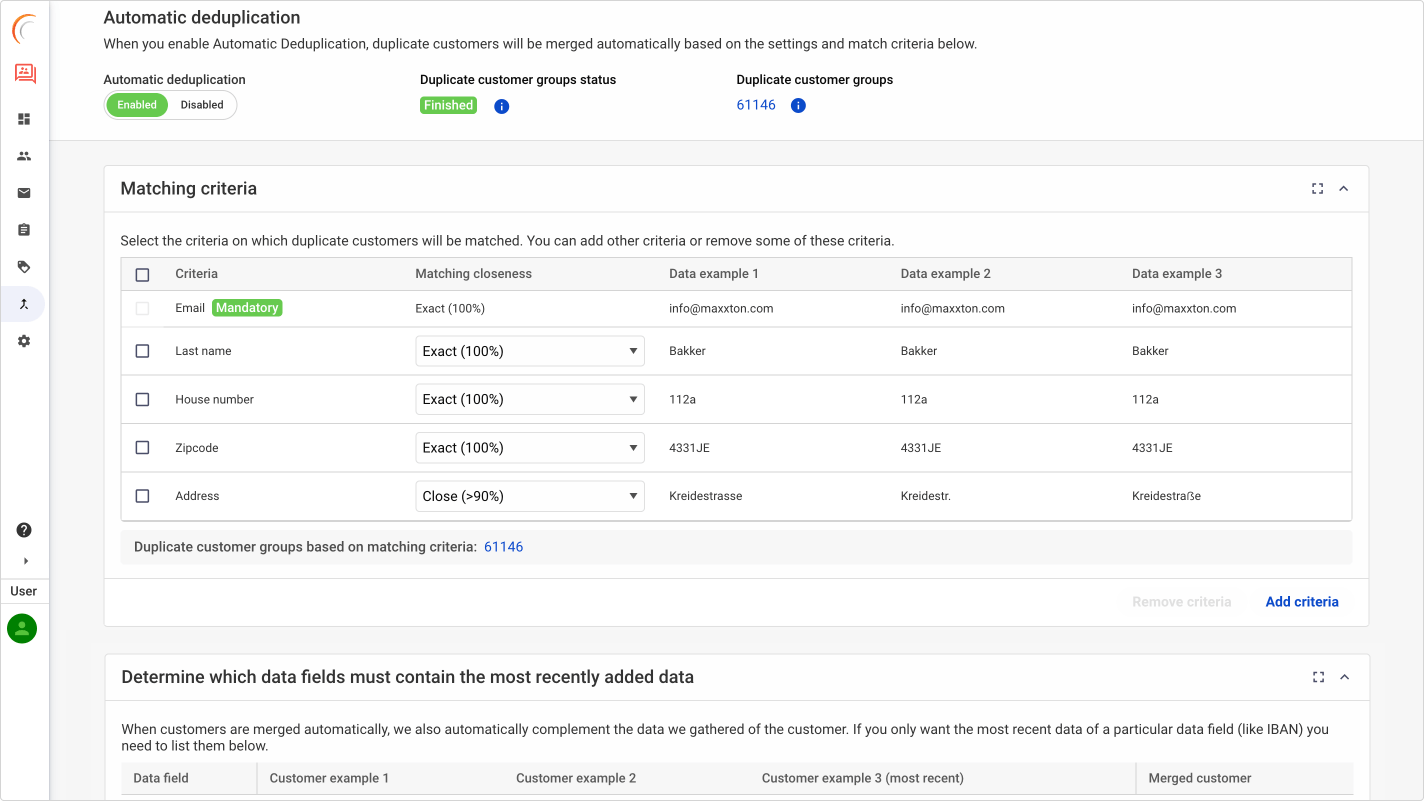
Notre outil fusionne de manière transparente les entrées identiques, mettant à jour les données avec les informations les plus actuelles et pertinentes. Pour une gestion optimale, une limite journalière de fusions automatiques est conseillée, permettant un contrôle rigoureux des résultats. Cet outil joue un rôle crucial dans l’atteinte d’une précision de correspondance, en particulier pour respecter un seuil de similarité de 100%. Un suivi des tailles de groupes de déduplication est recommandé, avec une intervention manuelle pour les cas plus complexes. Notre engagement envers la transparence se manifeste également dans la traçabilité des fusions, offrant une clarté et une organisation exemplaires dans la gestion des données.
Notre procédure, évaluée par une organisation indépendante spécialisée dans la protection des données et le RGPD, assure une approche de travail efficace et responsable vis-à-vis des informations personnelles.
Notre fonctionnalité de Déduplication Client par IA marque une avancée significative dans la gestion et l’intégrité des données. En exploitant les capacités de la data science, vous permettez à votre entreprise de maintenir une vue unique et précise de vos clients, d’améliorer l’efficacité opérationnelle et de favoriser une prise de décision basée sur les données. Avec cet outil innovant, vous pouvez vous concentrer sur l’essentiel : renforcer les relations clients et stimuler une croissance durable, tout en respectant la confidentialité des données et les exigences de conformité.
Veuillez vous inscrire à la newsletter Maxxton et rester connecté avec les dernières nouvelles et idées clés.


