
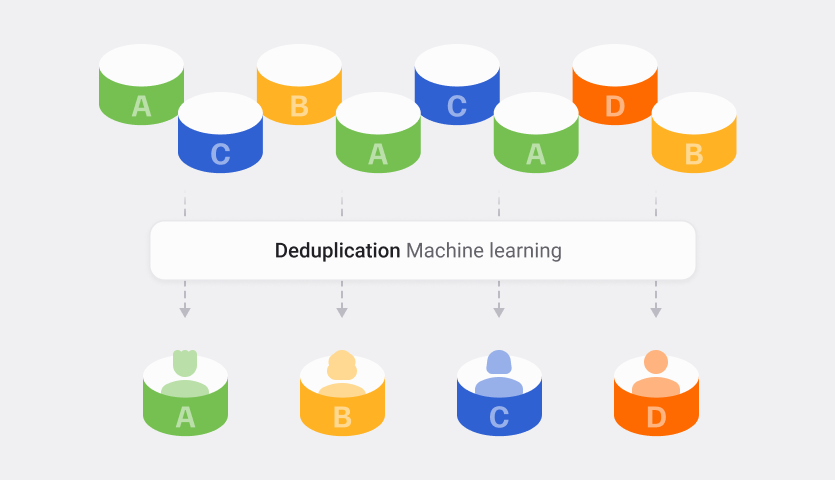
Imagine the challenges posed by multiple records of the same person in your database. Sorting through and eliminating these duplicates is a sizable and error-prone task. However, machine learning offers a solution.
If you are excited about launching campaigns or crafting strategic reports, here is a key point to consider: the risk of encountering corrupt or duplicated data.
Understanding the challenge
As businesses accumulate data from various sources and channels, the likelihood of encountering duplicate records increases significantly. These duplicates can arise from typos, variations in data entry, database mergers, or even changes in customer information over time. Left unchecked, duplicate customer records can compromise relationships, lead to missed opportunities, and ultimately impact revenue.
Benefits of customer deduplication
Implementing customer deduplication using machine learning provides multiple benefits:
- Enhanced data accuracy – Eliminating duplicate records ensures a more accurate database, facilitating reliable reporting and analytics.
- Optimised operations – Streamlined customer data leads to improved marketing campaigns, personalised experiences, and more efficient customer service.
- Compliance and privacy – Deduplication ensures that sensitive customer information is managed correctly, supporting data protection regulations.
- Cost savings – Reducing duplicates minimises unnecessary communications and resource wastage, resulting in cost efficiencies.
- Strategic insights – Clean, consolidated data enables deeper insights into customer behaviour and preferences, aiding data-driven decision-making.

Harnessing the power of machine learning
Our new software feature leverages machine learning and data science to systematically identify and manage duplicate customer records within Maxxton’s Customer Care module. By analysing intricate patterns within your data, the system intelligently discerns true customer identities from coincidental similarities. The machine learning process unfolds in seven steps, providing a seamless path to optimising your data landscape.
1. Data preprocessing
The first step involves preprocessing raw customer data to eliminate inconsistencies, standardise formats, and improve data quality. Examples include converting text to uppercase, applying consistent templates for phone numbers, and removing special characters such as umlauts or diacritics. This process establishes the foundation for precise deduplication.
2. Feature extraction
Key features such as names, addresses, phone numbers, and email addresses are extracted from customer records. These attributes serve as the basis for assessing similarity between records.
3. Similarity calculation
Machine learning algorithms calculate the similarity between pairs of customer records. The system evaluates multiple factors, assigning higher weights to features that are more reliable identifiers.
4. Rules customisation
To ensure flexibility, the system allows custom rules to be set for each client. These rules specify conditions such as requiring an exact email match or a minimum similarity threshold for last names (e.g., 90%). This customisation ensures adaptability to business needs.
For example, we account for common typos in front-office or telephone bookings, such as variations like Lynn, Linn, and Lin. Similarly, country-specific characters can create discrepancies, such as Kreidestrasse – Kreidestr. – Kreidestraẞe. The system determines whether such variations result from typos or indicate different individuals or addresses.
5. Threshold determination
The calculated similarity scores are compared against a predefined threshold. Records exceeding this threshold are flagged as potential duplicates.
6. Manual review and confirmation
To prevent false positives, flagged records are not automatically merged. Instead, they are presented for user review, ensuring that no genuine customer data is inadvertently altered.
7. Continuous learning
The system provides suggestions for merging records, while users provide feedback by accepting or rejecting changes. This input helps refine the system’s recommendations over time. The machine learning model continuously learns and improves, enhancing accuracy with each iteration.
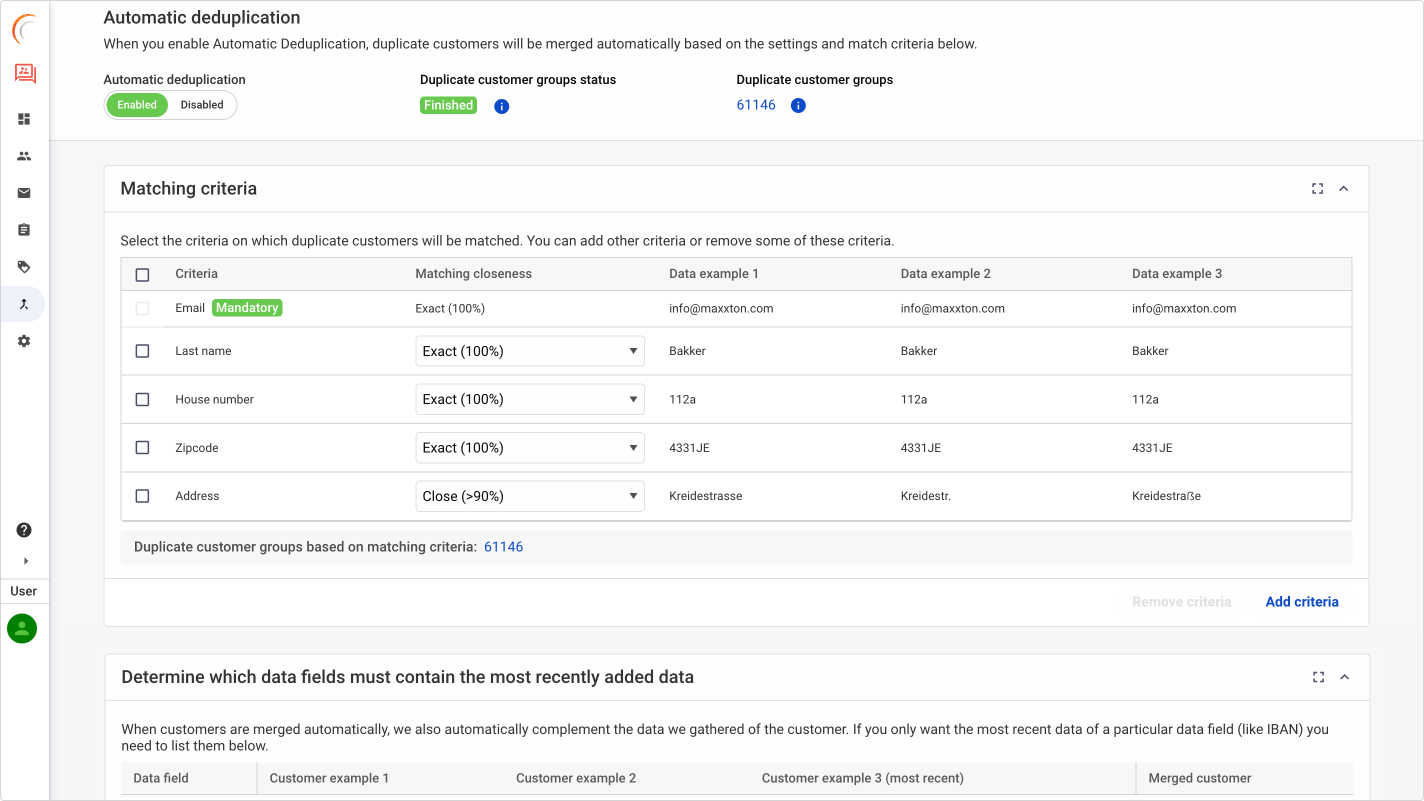
Automatic deduplication
Automatic deduplication is a valuable tool for precision matching when a 100% threshold is reached. This feature efficiently merges duplicates, ensuring that the consolidated data retains the most relevant and up-to-date information.
To maintain oversight, it is advisable to impose restrictions on the number of automatic merges per day, allowing for periodic review. You can also control the size of deduplication groups, reserving manual intervention for larger clusters. The tool ensures full transparency by maintaining traceability, clearly identifying merged records and selected data to ensure accountability in data management.
Data privacy and compliance
An independent organisation specialising in user data, privacy, and GDPR conducts audits and verifies compliance with current regulations. This ensures that personal data is handled responsibly, maintaining an effective and legally compliant workflow.
Conclusion
Customer deduplication using machine learning feature represents a significant advancement in data integrity and management. By harnessing the capabilities of data science, we empower businesses to maintain a single, accurate view of their customers, improving operational efficiency and enabling data-driven decision-making.
With this innovative tool at your disposal, you can focus on what matters most: building stronger customer relationships, driving sustainable growth, and ensuring data privacy and compliance.