
Stel je eens voor: dezelfde gast duikt meerdere keren op in je systeem. Het ene keer als Jan Jansen, de andere keer als J. Jansen met een ander e-mailadres.
Voor je het weet, heb je verschillende gastprofielen van dezelfde persoon. En die samenvoegen? Dat is vaak tijdrovend en foutgevoelig. Gelukkig kan machine learning nu dit werk overnemen.
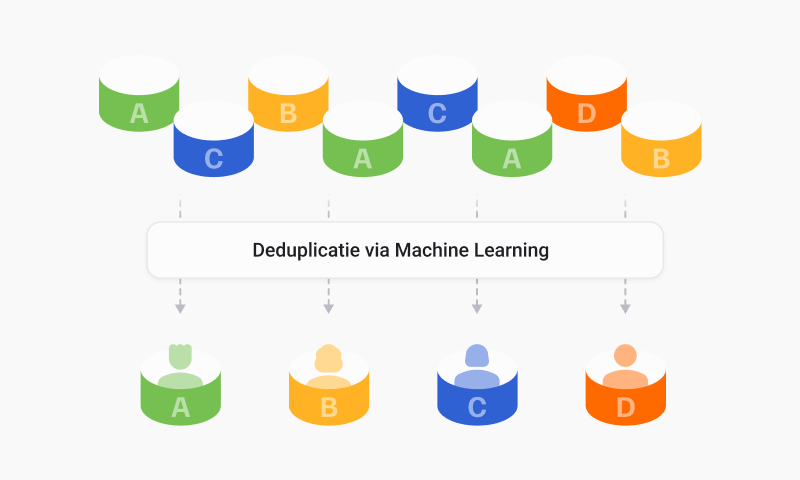
Voor iedereen die enthousiast is over het lanceren van campagnes of het opstellen van strategische rapporten, is dit een belangrijk aandachtspunt: het risico op corrupte of gedupliceerde data.
De uitdaging begrijpen
Wanneer bedrijven data verzamelen via verschillende bronnen en kanalen, neemt de kans op duplicaten aanzienlijk toe. Deze kunnen ontstaan door typefouten, variaties bij invoer, samenvoegingen van databases of wijzigingen in klantinformatie in de loop van de tijd. Als deze duplicaten niet worden aangepakt, kunnen klantrelaties worden geschaad, kansen worden gemist en inkomsten worden beïnvloed.
Voordelen van klantdeduplicatie
Het implementeren van klantdeduplicatie met behulp van machine learning levert meerdere voordelen op:
-
Verbeterde datanauwkeurigheid – Het verwijderen van duplicaten zorgt voor een accuratere database, wat betrouwbare rapportages en analyses mogelijk maakt.
-
Geoptimaliseerde processen – Gestroomlijnde klantdata leidt tot betere marketingcampagnes, gepersonaliseerde ervaringen en efficiëntere klantenservice.
-
Compliance en privacy – Deduplicatie zorgt voor correct beheer van gevoelige klantgegevens in overeenstemming met regelgeving voor gegevensbescherming.
-
Kostenbesparing – Minder duplicaten betekent minder onnodige communicatie en minder verspilling van middelen, wat leidt tot kostenbesparing.
-
Strategische inzichten – Schone, geconsolideerde data biedt diepere inzichten in klantgedrag en voorkeuren, wat datagedreven besluitvorming ondersteunt.

De kracht van machine learning benutten
De nieuwe softwarefunctie maakt gebruik van machine learning en data science om duplicaten in klantgegevens systematisch te identificeren en beheren binnen de Customer Care module van Maxxton. Door verbanden in de data te analyseren, voegt het systeem de juiste gegevens samen en voorkomt het dat verschillende mensen door elkaar worden gehaald. Het proces bestaat uit zeven stappen en biedt een gestroomlijnd pad naar een geoptimaliseerd datalandschap.
1. Voorbewerking van data
De eerste stap betreft het voorbewerken van ruwe klantgegevens om inconsistenties te verwijderen, formaten te standaardiseren en de datakwaliteit te verbeteren. Voorbeelden zijn het omzetten van tekst naar hoofdletters, het toepassen van consistente templates voor telefoonnummers en het verwijderen van speciale tekens zoals umlauten of diakritische tekens. Deze stap vormt de basis voor nauwkeurige deduplicatie.
2. Extractie van kenmerken
Belangrijke kenmerken zoals namen, adressen, telefoonnummers en e-mailadressen worden uit de klantrecords gehaald. Deze vormen de basis voor het beoordelen van overeenkomsten tussen records.
3. Overeenkomstberekening
Machine learning-algoritmen berekenen de overeenkomst tussen paren klantrecords. Het systeem evalueert meerdere factoren en kent zwaardere weging toe aan kenmerken die betrouwbaarder zijn als identificator.
4. Aanpassing van regels
Voor maximale flexibiliteit laat het systeem toe dat klanten eigen regels instellen. Deze regels kunnen bijvoorbeeld vereisen dat e-mailadressen exact overeenkomen, of dat een minimumovereenkomst van 90% wordt bereikt voor achternamen. Deze aanpassing zorgt voor afstemming op de bedrijfsbehoeften.
Zo wordt rekening gehouden met veelvoorkomende typefouten bij frontoffice- of telefonische boekingen, zoals Lynn, Linn en Lin. Ook land-specifieke tekens kunnen variaties veroorzaken, bijvoorbeeld Kreidestrasse – Kreidestr. – Kreidestraẞe. Het systeem bepaalt of het gaat om typefouten of daadwerkelijk verschillende personen of adressen.
5. Drempelbepaling
De berekende overeenkomsten worden vergeleken met een vooraf ingestelde drempel. Records die deze drempel overschrijden, worden gemarkeerd als mogelijke duplicaten.
6. Handmatige controle en bevestiging
Om foutieve samenvoegingen te voorkomen, worden gemarkeerde records niet automatisch samengevoegd. Ze worden eerst ter beoordeling aan de gebruiker voorgelegd om te garanderen dat geen authentieke klantdata per ongeluk wordt gewijzigd.
7. Voortdurende verbetering
Het systeem doet voorstellen voor samenvoeging van records. Gebruikers geven feedback door deze voorstellen te accepteren of af te wijzen. Die input helpt het systeem bij het verfijnen van toekomstige aanbevelingen. Het machine learning-model blijft leren en verbeteren, waardoor de nauwkeurigheid met elke iteratie toeneemt.

Automatische deduplicatie
Automatische deduplicatie is bijzonder geschikt voor exacte matches met een overeenkomstdrempel van 100%. In deze gevallen worden duplicaten efficiënt samengevoegd, waarbij de meest relevante en actuele informatie behouden blijft.
Voor transparantie en controle is het raadzaam om limieten in te stellen voor het aantal automatische samenvoegingen per dag. Periodieke controle blijft zo mogelijk. Ook kan de grootte van deduplicatiegroepen worden beheerd, waarbij grotere clusters handmatig worden beoordeeld. Het systeem biedt volledige traceerbaarheid, zodat altijd duidelijk is welke gegevens zijn samengevoegd en op basis waarvan.
Gegevensprivacy en compliance
Een onafhankelijke organisatie gespecialiseerd in gebruikersdata, privacy en GDPR voert audits uit en verifieert of de processen voldoen aan de geldende regelgeving. Dit garandeert dat persoonsgegevens op een verantwoorde manier worden behandeld binnen een effectief en wettelijk compliant proces.
Conclusie
Klantdeduplicatie met behulp van machine learning betekent een grote vooruitgang op het gebied van datakwaliteit en -beheer. Door de kracht van data science te benutten, kunnen organisaties een eenduidig en accuraat klantbeeld behouden, operationele efficiëntie verbeteren en datagedreven keuzes maken.
Deze innovatieve tool stelt organisaties in staat zich te richten op wat echt telt: het versterken van klantrelaties, het stimuleren van duurzame groei en het waarborgen van privacy en compliance.